


文本到图像(txt2img)是指使用人工智能模型从文本输入生成图像的过程。目前市面上有许多txt2img AI可供使用。通过调整txt2img设置,可以控制图像生成的过程。
如何工作的文本到图像模型?
txt2img模型是一种神经网络,它输入自然语言文本并产生与文本匹配的图像。在Stable Diffusion和其他AI图像模型中,文本输入被称为提示(prompt)和负提示(negative prompt)。
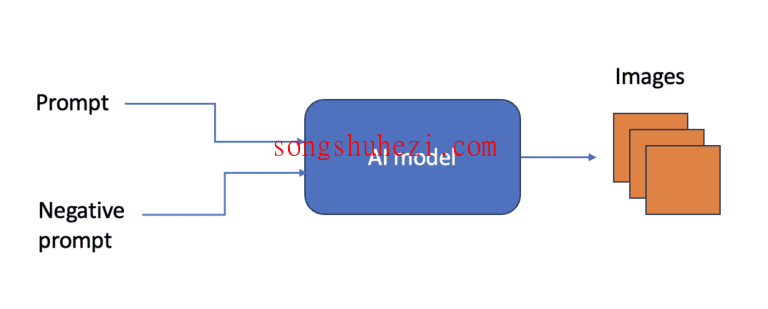
txt2img生成流程:
- txt2img AI模型接受提示和负提示作为输入,并输出图像。
- 由于概率输出,同一提示和负提示可以产生多张图像,因为许多图像都可以匹配提示。
如何使用文本到图像?
文本到图像是AI图像生成器(包括Stable Diffusion)的最基本功能。你可以在线使用免费的生成器。
在AUTOMATIC1111Stable DiffusionWebUI中,你可以在txt2img页面使用文本到图像。
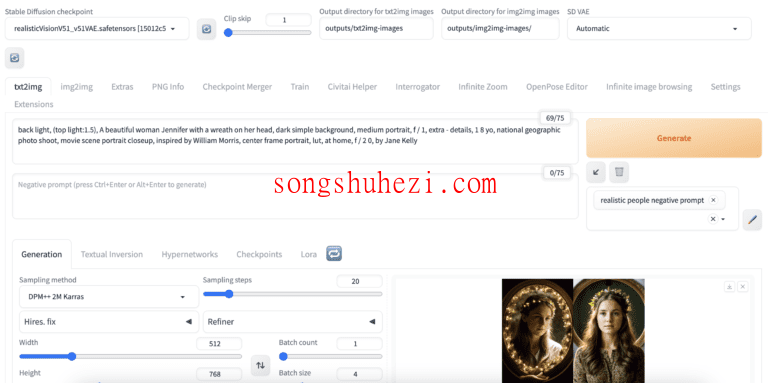
Stable Diffusion文本到图像设置解释
对于Stable Diffusion,以下设置会影响txt2img的结果:
-
检查点模型:Stable Diffusion模型显著影响风格。例如,使用像Realistic Vision这样的写实模型来生成写实人物。
-
提示:描述你希望在图像中看到什么的文本输入。
-
负提示:描述你不希望看到什么的文本输入。
-
图像大小:图像大小应与检查点模型匹配。v1模型的VAE大小是512×512,SDXL模型是1024×1024。
- 图像大小与宽高比例。
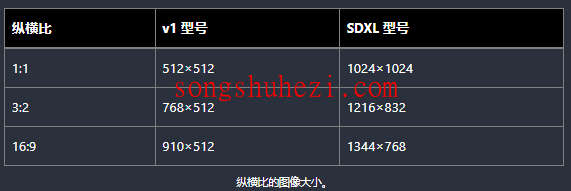
-
采样方法:在扩散过程中去噪图像的方法。如果你刚开始,不需要更改它。
-
采样步骤:离散化去噪处理的步骤数量。更高的值使去噪过程更准确,因此质量更高。至少设置为20。
-
CFG比例:分类器自由引导比例控制应多紧密地遵循提示。
- 1 – 大部分忽略你的提示。
- 3 – 更具创造性。
- 7 – 在遵循提示和自由之间取得良好平衡。
- 15 – 更多地遵循提示。
- 30 – 严格遵循提示。
如果设置得太高,可能会看到颜色问题。
txt2img模型是如何训练的?
训练数据和方法与AI模型架构同等重要。现代的txt2img模型都是用大量的图像和标题对数据集训练的。通过学习图像和标题之间的相关性,AI模型学会了生成与提示匹配的图像。
文本到图像AI模型
虽然Stable Diffusion是众所周知的txt2img模型之一,但它当然不是唯一的。你将在这一节中学习一些重要的txt2img模型。
- DALL·E:OpenAI的DALL·E是首批获得广泛公众关注的txt2img模型之一。尽管与今天的标准相比,其图像生成可能看起来原始,但在2021年发布时,它是一个巨大的突破。我们第一次能够用自然语言描述生成图像。

- Imagen:Google开发的Imagen文本到图像模型是一个生成写实图像的中性网络扩散模型。模型架构和基准在《Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding》一文中发布。

- Stable Diffusion:Stable Diffusiontxt2img模型是最受欢迎的开源文本到图像模型。虽然Imagen提供了更优越的性能,但它需要高性能的计算机来运行,因为扩散过程是在像素空间中进行的。

- Midjourney:Midjourney是其母公司提供的图像生成服务的专有txt2img模型。关于模型架构没有披露太多信息。

以上是关于文本到图像(txt2img)的基本介绍和使用说明。
阅读全文
