


CogAgent是什么?
CogAgent是一个由清华大学智谱AI开发的基于CogVLM改进的新型视觉语言模型(VLM)。该模型专门设计用于理解和导航图形用户界面(GUI)。它采用了低分辨率和高分辨率图像编码器的双编码器系统,能够处理和理解复杂的GUI元素和文本内容。
CogAgent-18B拥有110亿的视觉参数和70亿的语言参数, 支持1120*1120分辨率的图像理解。在CogVLM的能力之上,它进一步拥有了GUI图像Agent的能力。
CogAgent-18B 在9个经典的跨模态基准测试中实现了最先进的通用性能,包括 VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, 和 POPE 测试基准。它在包括AITW和Mind2Web在内的GUI操作数据集上显著超越了现有的模型。
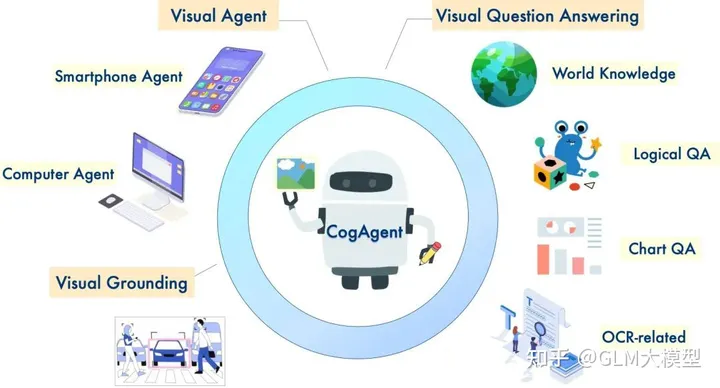
CogAgent可以做什么?
CogAgent的主要功能是提高GUI的交互效率和准确性。它能够识别和解释小型GUI元素和文本,这对于有效的GUI交互至关重要。CogAgent在多个任务中表现优于现有的基于大型语言模型的方法,尤其是在PC和Android平台的GUI导航方面。此外,它还在多个文本丰富和一般视觉问答基准上表现出色。潜在应用包括自动化GUI操作(如点击按钮、输入文本和选择菜单)、提供GUI帮助和指导,以及开发新的GUI设计和交互方式。
CogAgent 的潜在应用包括:
- 自动化 GUI 操作,例如点击按钮、输入文本和选择菜单。
- 提供 GUI 帮助和指导,例如解释功能和提供操作说明。
- 开发新的 GUI 设计和交互方式。
CogAgent 仍处于早期开发阶段,但其潜在影响是巨大的。该模型有可能彻底改变我们与计算机交互的方式。
如何使用CogAgent?
CogAgent对外开放了论文、代码,提供了在线体验功能:
温馨提示:
