


MuseV是一个基于扩散模型的虚拟人视频生成框架,利用全新的视觉条件并行去噪技术,支持生成无限长度的视频。
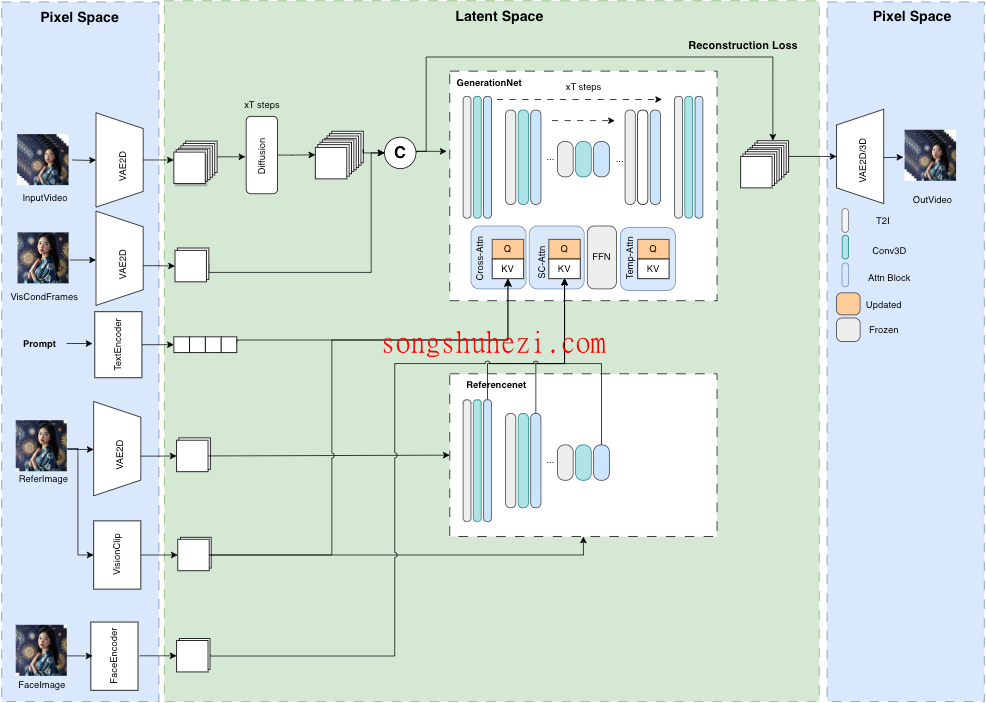
这一框架兼容Stable Diffusion生态系统,并引入了多参考图像技术,如IPAdapter和ReferenceNet,提升了视频生成的多样性和适应性。MuseV的开发团队希望通过开源这一项目,为社区带来更广泛的利益。
1. 功能概述
- 无限长度视频生成:采用视觉条件并行去噪技术,打破了传统视频长度的限制。
- 支持多种内容转换模式:包括Image2Video、Text2Image2Video和Video2Video,满足不同场景的需求。
- 多参考图像技术:集成IPAdapter、ReferenceOnly等技术,提高生成视频的准确性和真实感。
2. 快速开始
- 环境要求:推荐使用Python环境,支持通过Docker容器进行快速部署。
- 模型和数据下载:可以从官方Huggingface账户下载预训练模型和数据集。
3. 实际应用和演示
- Gradio界面:提供Gradio脚本,本地生成GUI界面,用户可以直接在界面上生成视频。
- 应用案例:MuseV已经成功应用于生成各种虚拟人视频,如演讲、表演等。

MuseV是一款强大的工具,适合任何需要高质量视频内容的创作者或研究人员使用。无论是视觉效果还是动作的自然流畅性,MuseV都展现了高水平的技术实力。此外,MuseV支持的视频长度和内容自由度,为创作提供了更广阔的空间。
×

直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
验证码:
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“AI工具教程”或者“chatgpt8080” 或微信扫描右侧二维码关注微信公众号
温馨提示:
