


声音克隆技术已不再遥不可及!coqui.ai推出的xtts_v2模型,基于Coqui Public Model License 1.0.0开源协议,为用户们提供了一种全新的声音转换方式。本工具支持多种语言,包括中文、英文、日语等共16种语言,用户可以轻松将文本或声音转换成指定音色的声音。
安装教程,一步到位:
准备工作:
- 确保你的电脑连接了稳定的网络。
下载软件:
- 访问工具的官方发布页面,找到最新的预编译版本下载链接。
- 下载包括主程序(app.exe,大约1.7G)和模型文件(大约3G)。
解压安装:
选择一个容易找到的文件夹,比如E:/clone-voice,将下载的文件解压到这里。解压后,你会看到主程序和一个tts文件夹,确保模型文件也放到这个文件夹内。
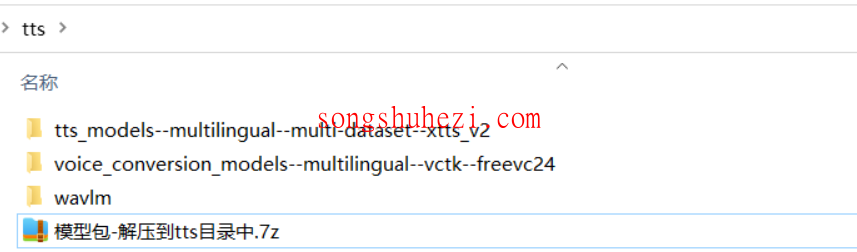
启动程序:
双击app.exe,程序会自动尝试打开一个web界面。
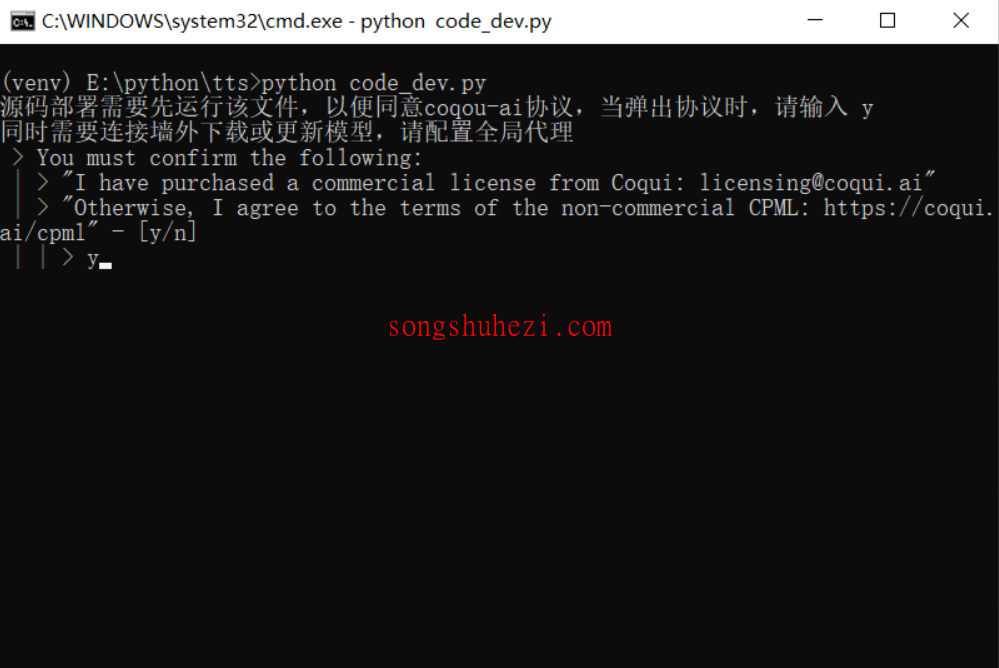
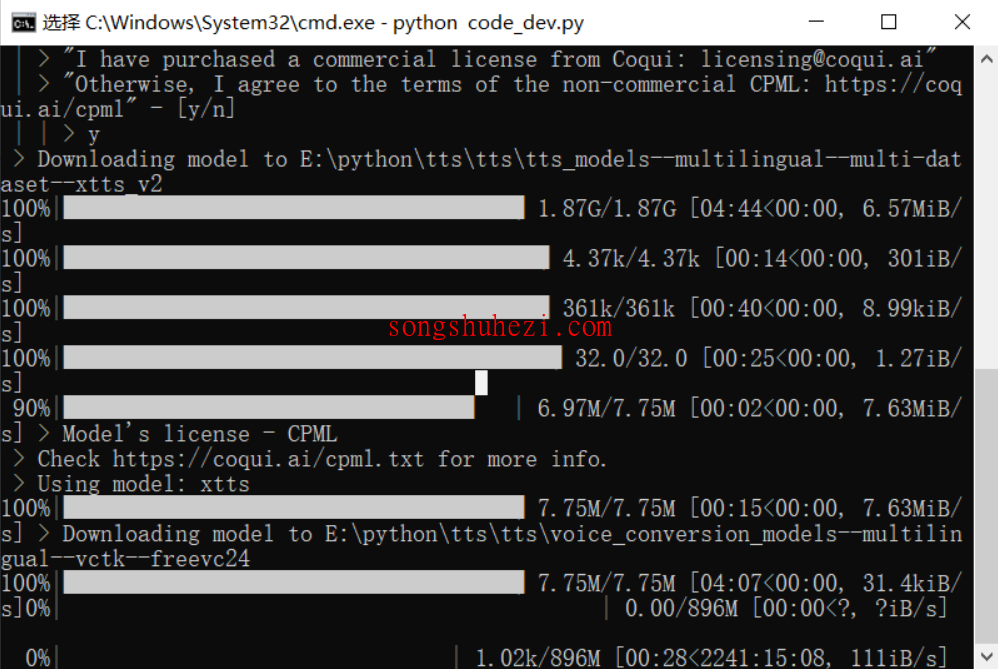
如果看到命令提示符窗口(cmd窗口)有任何错误提示,先不要慌,通常都是小问题。
配置环境(仅限于源码部署用户):
- 在
.env文件中设置HTTP代理,比如HTTP_PROXY=http://127.0.0.1:7890,确保你的代理可靠。 - 安装Python 3.9到3.11版本,并确保
git-cmd等工具已安装。
声音克隆:
在web界面上,你可以选择“文字->声音”或“声音->声音”模式进行声音克隆。
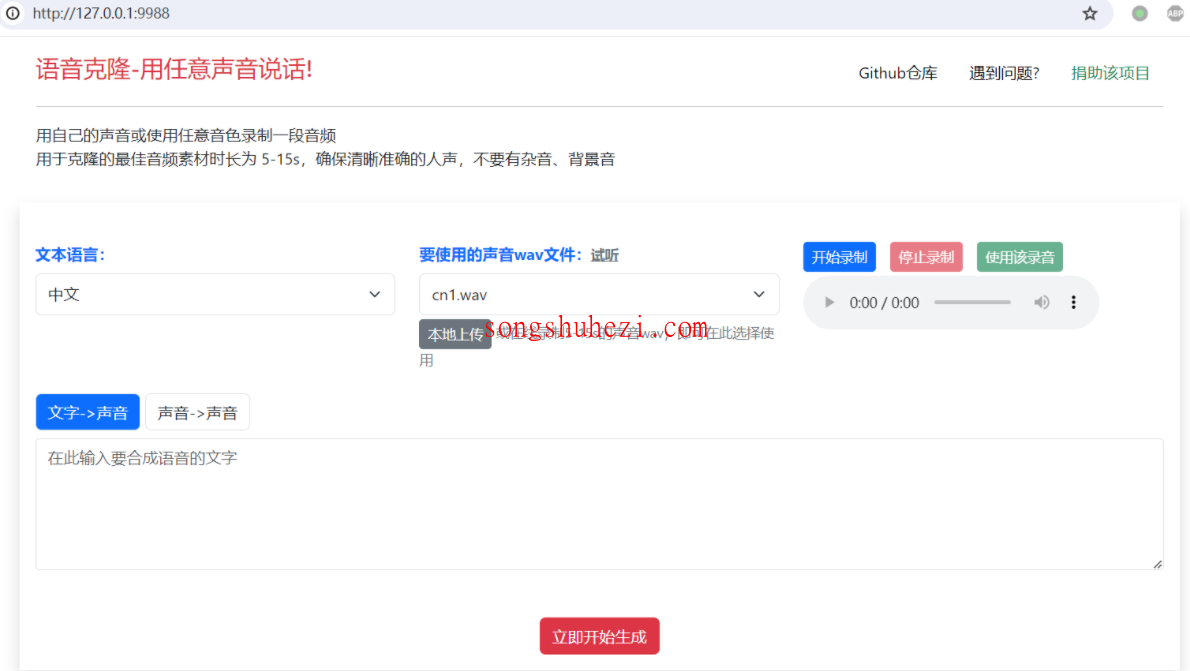
根据提示上传文字或音频文件,选择目标音色,然后点击“立即开始”。
上传之后就可以听到用选定音色合成的声音了,如果你的电脑支持CUDA加速,转换过程会更快。
最后给大家提个小建议,如果你想获得最佳的效果,录制的声音时长建议在5到20秒之间,尽量确保环境安静,减少背景噪音。要是你有NVIDIA显卡的话,可以安装CUDA Toolkit和对应的cudnn,让你体验起来更加的畅快。
×

直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
验证码:
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“AI工具教程”或者“chatgpt8080” 或微信扫描右侧二维码关注微信公众号
温馨提示:
