



一、AudioGPT是什么?
AudioGPT是一个理解和生成语音、音乐、声音等内容的多模态AI系统,将Chat-GPT与音频基础模型相结合,以处理复杂的音频信息和支持口头对话,在多轮对话中展现出强大的音频理解和生成能力,使用户可以轻松地创建丰富多样的音频内容。
由浙江大学、北京大学、卡内基梅隆大学和中国人民大学的研究人员提出的全新音频理解与生成系统 AudioGPT。
AudioGPT 以 Chat-GPT 充当负责对话与控制的大脑,语音基础模型协同以完成跨模态转换、以及音频 (语音、音乐、背景音、3D 说话人) 模态的理解、生成,能够解决 20 + 种多语种、多模态的 AI 音频任务。
功能示例:


二、AudioGPT可以做什么?
它还可以执行许多其他任务,例如:
- 音频转录;
- 图像中的音乐和声音;
- 来自音频文件的说话头部视频。
还有更多:
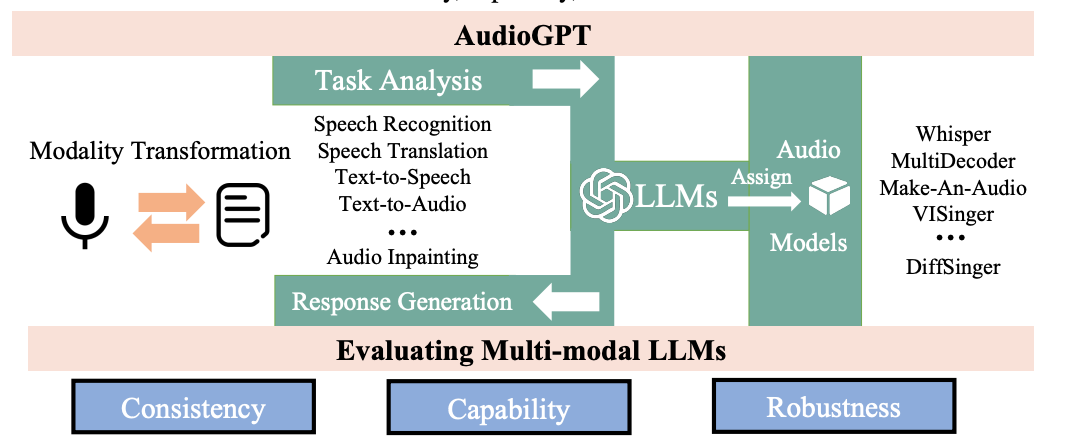
三、工作流程
AudioGPT 包括四个关键步骤:
- 模态转换:使用语音识别系统将语音输入转换为文本。
- 任务分析:使用Chat-GPT 了解用户的请求。
- 模型分配:从一组 17 个模型中选择合适的 AI 模型来处理特定任务。
- 响应生成:以不同的方式(音频、文本、图像、视频)生成输出并将其呈现给用户。
四、AudioGPT局限性
尽管 AudioGPT 具有令人印象深刻的功能,但它也有一些局限性:
- 它不是专门为音乐而建的。
- 它仍在进行中,在任务分配和理解用户需求方面还有一些改进空间。
对音乐制作未来的影响
AudioGPT 等 AI 作曲和制作助手有可能极大地改变音乐家的工作方式。通过使用音乐模型扩展 AudioGPT 或创建单独的 MusicGPT,并开发用于集成到数字音频工作站 (DAW) 中的插件,AI 驱动的音频工具可能成为音乐家的宝贵资源。这将增强而不是取代人类在音乐制作中的创造力和表现力。
五、如何使用?
- 试用模型:https://huggingface.co/spaces/AIGC-Audio/AudioGPT
- GitHub地址:https://github.com/AIGC-Audio/AudioGPT
- 论文地址:https://arxiv.org/abs/2304.12995
本模型暂时只能用于非商业用途。
温馨提示:
