



Ferret是什么?
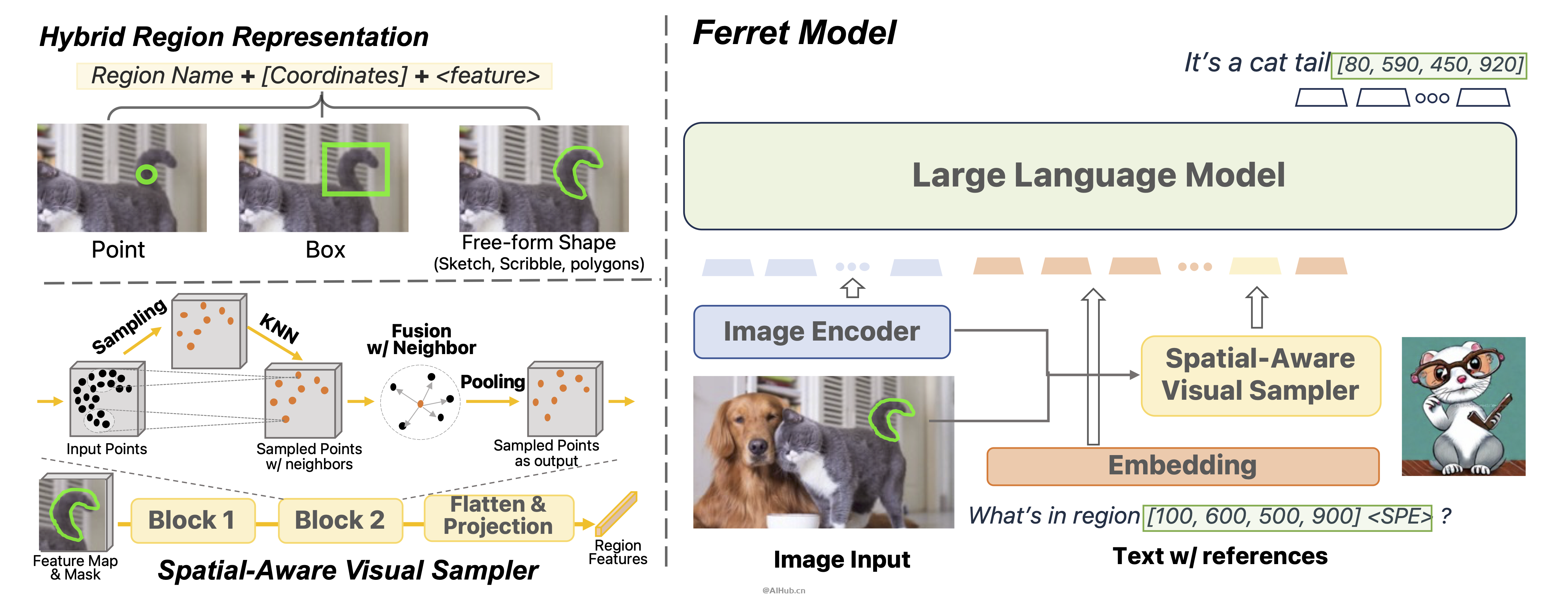
Ferret是苹果公司开发的端到端机器学习语言模型,Ferret不仅可以准确识别图像并描述其内容,还能够识别和定位图像中的各种元素,无论你用怎样的方式描述图像内容,Ferret都能准确地在图像中找到并识别出来。Ferret结合了混合区域表示和空间感知的视觉采样器,使得在MLLM中实现细粒度和开放词汇的指代和定位成为可能。
Ferret拥有7B和13B两个版本,为了增强 Ferret 模型的能力,苹果特别收集了一个包含1.1M个样本的GRIT 数据集。
Ferret的主要功能和特点
Ferret能够理解和处理图像与文本之间的复杂关系。这个模型的特别之处在于它能够识别和定位图像中的各种元素,无论这些元素是什么形状或大小。
- 多模态理解:Ferret结合了自然语言处理和计算机视觉技术,能够理解复杂的语言指令,并在图像中找到具体的物体或区域。
- 细粒度定位:它能够在非常精确的层面上,根据文字描述在图片中定位和识别物体,甚至是图片中的一小部分。
- 开放词汇的应用:Ferret支持开放词汇的处理,这意味着它能够理解和响应各种各样的、未预先定义的语言表达。
- 大规模数据集:它使用了一个名为GRIT的大规模数据集,这个数据集包含了大量的实例,用于训练和提高模型的准确性和效率。
- 多模态评估基准:Ferret-Bench是一个综合性的评估工具,用于测试模型在理解语言、图像处理、知识获取和逻辑推理等多个方面的能力。
- 适用于复杂任务:Ferret特别适合于需要综合处理语言和视觉信息的复杂任务,如自动图像标注、智能搜索和内容创建等。
- 灵活性和适应性:由于其开放词汇和细粒度处理的能力,Ferret在多种场景下都有很好的适应性和应用潜力。
Ferret适用场景
由于Ferret强大的图像和文本处理能力,Ferret 适用于多种应用场景,包括图像搜索、自动图像标注、交互式媒体探索等。
Ferret适用人群
Ferret适合机器学习研究人员、开发者和任何对先进的自然语言处理和计算机视觉技术感兴趣的人。它特别适用于那些在自然语言理解、图像处理和多模态机器学习领域工作的专业人士。
温馨提示:
