



MovieLLM是什么?
MovieLLM 是一个由复旦大学和腾讯PCG共同开发的,旨在通过AI生成的电影来增强长视频理解的框架。它可以在各种场景上生成具有风格一致的视频画面,解决在生成长视频时的高质量数据的问题。
MovieLLM利用GPT-4和引导式文本到图像生成模型来创建一致的关键帧,这些关键帧具有固定的风格,并且与合理的对话和问答对相对应。这些数据被用于训练多模态大型语言模型,以提高其在理解复杂视频叙事方面的表现。

MovieLLM的主要功能
MovieLLM的主要特点和功能有:
- 合成数据生成:MovieLLM通过GPT-4生成详细的剧本和相应的视觉内容,解决了高质量、多样化长视频数据缺乏的问题。
- 风格一致性:通过文本反转技术,将剧本中生成的风格描述固定到扩散模型的潜在空间,确保生成的场景在统一的审美下保持多样性。
- 多模态模型训练:结合GPT-4的强大生成能力和风格引导扩散模型,产生风格一致的关键帧和问答对,形成一个全面的指导调整语料库,将视觉数据与问答对结合起来。
- 实验验证:广泛的实验表明,MovieLLM生成的数据显著提高了多模态模型在理解复杂视频叙事方面的性能,克服了现有数据集在稀缺性和偏见方面的局限性。
- 灵活性和可扩展性:MovieLLM的方法在灵活性和可扩展性方面优于传统的数据收集方法,为长视频数据的生成提供了一种新的替代方案。
这个项目为视频理解和多模态AI研究提供了一个新的方向,通过合成数据的生成,有助于推动相关技术的发展。
MovieLLM的工作原理
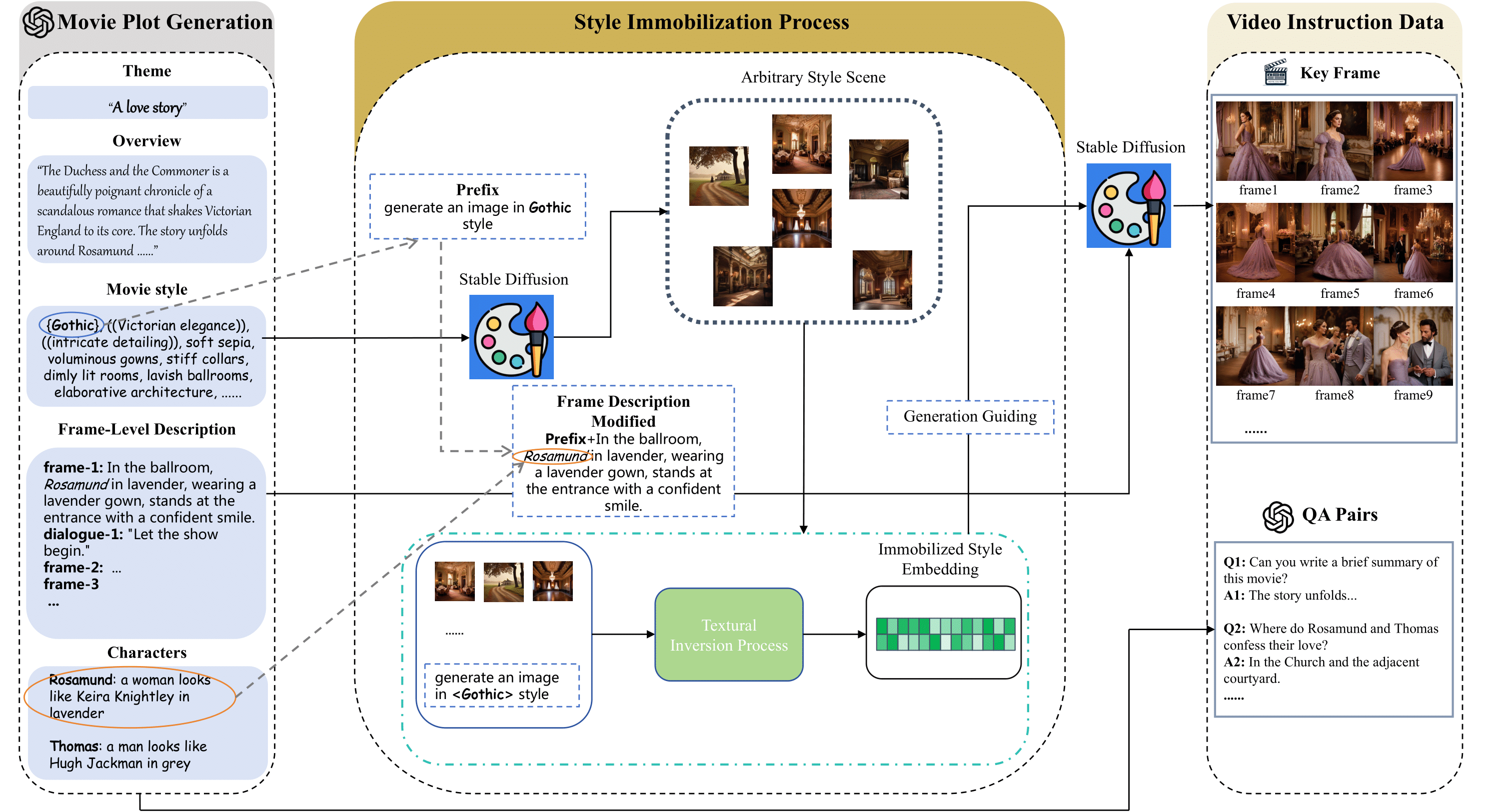
1、我们利用 GPT-4 的功能来生成合成数据,而不是限制绘图生成到传统数据源(例如网络或现有数据集)。通过提供主题、概述和样式等特定元素,我们指导 GPT-4 生成适合后一代流程的电影级关键帧描述。
2、通过巧妙地采用文本反转,我们将从脚本生成的风格描述固定到扩散模型的潜在空间上。这种方法引导模型生成固定风格的场景,同时在统一的审美下保持多样性。
3、通过将 GPT-4 强大的生成能力与开发的风格引导扩散模型相结合,我们生成风格一致的关键帧和相应的 QA 对,从而形成一个全面的指令调优语料库,将视觉数据与 QA 对相结合。
如何使用MovieLLM?
MovieLLM相关资源地址,如感兴趣,请前往了解:
- 项目:https://deaddawn.github.io/MovieLLM/
- 论文:https://arxiv.org/pdf/2403.01422.pdf
- 代码:https://github.com/Deaddawn/MovieLLM-code
温馨提示:
