


-
Anakin.ai-无代码 AI 应用构建平台
Anakin.ai是什么? Anakin.ai是一个一站式无代码AI应用构建平台,提供内容创作、文案、问答、图像生成、视频生成、语音生成、智能Agent、自动化工作流、自定义AI应用等服务。它旨在定制专属的AI应用工作台,帮助用户轻松创建和使用AI应用,以提高工作效率和创造力。 产品官网:https://anakin.ai/zh-cn Anakin.ai可以做什么? Anakin.ai提供了一系列…- 25
- 0
-
Lumiere-谷歌发布的最新AI视频生成模型
Lumiere是什么? Lumiere是一个谷歌发布的文本到视频扩散模型,使用空间-时间U-Net架构一次性生成整个视频时间跨度,实现全局时间一致性。它能够直接生成全帧率、低分辨率视频,适用于多种内容创作和视频编辑应用,如图像到视频、视频修复和风格化生成。该模型在媒体和娱乐、教育、社交媒体和虚拟现实等领域具有广泛的应用前景。 官方发布了一些演示视频,如有兴趣,可前往项目地址查看。 项目地址:htt…- 57
- 0
-

AnimateDiff-Lightning:字节发布的快速生成视频的AI模型
AnimateDiff-Lightning是什么? AnimateDiff-Lightning是由字节跳动发布的高速文本到视频生成模型,采用渐进式对抗性扩散蒸馏技术,实现了快速、高质量的少步骤视频生成,只需要 4-8 步的推理就可以生成质量非常不错的视频。AnimateDiff-Lightning模型是从 AnimateDiff SD1.5 v2 中提炼出来的。 包含 1 步、2 步、4 步和 8…- 26
- 0
-
Feedeo-AI互动视频生成平台
目录 Toggle Feedeo是什么? Feedeo的主要功能 Feedeo的应用场景 Feedeo的产品价格 如何使用Feedeo创建互动视频? Feedeo是什么? Feedeo是一个在线AI互动视频生成平台,它允许用户通过上传照片、填写脚本并选择组件来轻松创建逼真的带有真实或卡通角色的互动视频。这个平台特别适用于生成互动视频,以吸引用户、展示产品、游戏化参与度和收集反馈。无需高昂费用聘请代…- 40
- 0
-

ActAnywhere-Adobe发布的视频生成模型
ActAnywhere是什么? ActAnywhere是一个由Stanford University和Adobe Research开发的AI模型,专注于自动化视频背景生成。它通过接收前景主体的分割序列和描述背景的图像作为输入,生成与前景主体运动相协调的视频背景。该模型利用大型视频扩散模型,并在大规模人类与场景互动视频数据集上进行训练,以实现高质量且符合创意意图的视频内容。ActAnywhere展示…- 31
- 0
-
MuseV-腾讯天琴实验室开源的虚拟人视频生成框架
MuseV是什么? MuseV是一个由腾讯音乐娱乐的天琴实验室开源的虚拟人视频生成框架,专注于生成高质量的虚拟人视频和口型同步。它利用先进的算法,能够制作出具有高度一致性和自然表情的长视频内容。MuseV支持自定义动作和风格,视频时长理论上无限,且生成速度快。这一技术在AI创作领域中表现出色,为虚拟人视频制作提供了新的可能性。 MuseV的主要特性 MuseV的主要特性包括: 图生视频和口型生成:…- 23
- 0
-
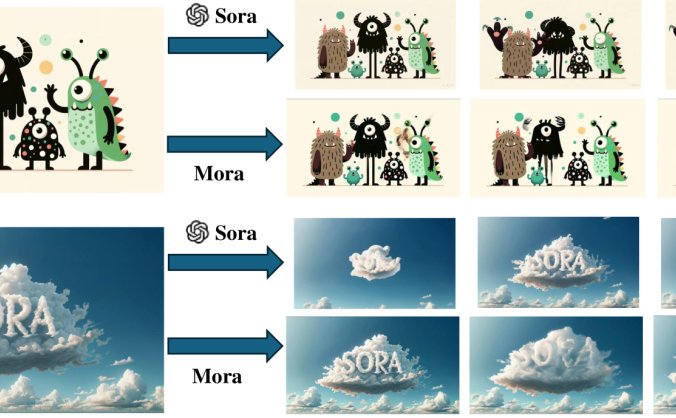
Mora-微软等推出的多智能体视频生成框架
Mora是什么? Mora是一个由里海大学和微软开发的多智能体(AI Agents)视频生成框架,旨在模仿OpenAI的Sora模型的通用视频生成能力。Mora通过分解视频生成任务到多个专业智能体,能够执行文本到视频的转换、视频编辑和扩展等多种视频生成任务。 论文地址:https://arxiv.org/abs/2403.13248 GitHub地址:https://github.com/lich…- 23
- 0
-

W.A.L.T:通过扩散模型生成逼真视频的AI模型
近日,谷歌与李飞飞的斯坦福团队携手推出了基于Transformer的视频生成模型W.A.L.T。该模型利用因果编码器和窗口注意的变压器架构,成功将图像和视频压缩到一个共享的潜在空间,实现了联合训练和生成。这一创新性的模型不仅在已建立的视频和图像生成基准测试上取得了SOTA,还展示了在文本到视频生成任务中的卓越性能。 这种方法有两个关键的设计决策。首先,它使用因果编码器共同压缩图像和视频,使其在统一…- 28
- 0
-
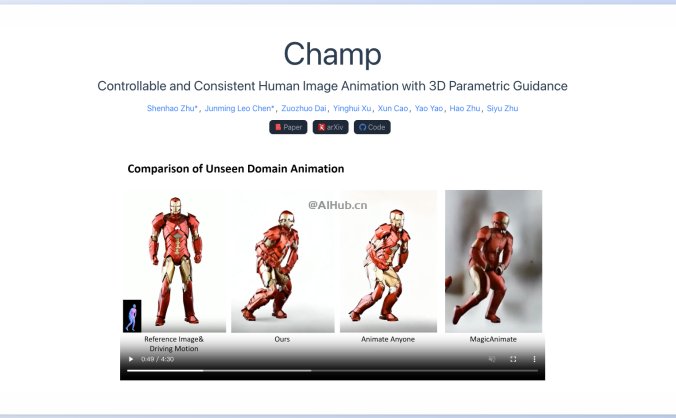
Champ-基于3D的人物图像到动画视频生成框架
Champ是什么? Champ是由阿里巴巴、南京大学和复旦大学的研究人员共同提出的一种旨在提供可控且与原始人物保持一致性的人物图像动画视频生成框架。Champ通过结合3D模型和潜在扩散框架,实现了对复杂人体几何和运动特征的精确捕捉。该项目在未见领域动画和跨身份动画转换方面展现出卓越性能,并计划开源代码,以推动该领域的进一步研究和应用。 项目地址:https://fudan-generative-v…- 26
- 0
-
Veo – Google推出的视频模型,可生成1分钟1080p视频
2024-05-15 09:06:58,Veo是什么? Veo 是 Google DeepMind 开发的先进视频生成模型,能够生成1080p高分辨率、长时长的高质量视频。它支持广泛的电影和视觉风格,准确捕捉提示的细微差别,并提供创意控制。Veo 旨在使视频制作更易于访问,解锁叙事、教育等领域的新可能性。 官方发布的使用视频演示: Veo的功能特点 高分辨率视频生成:Veo 能够生成高质量的 10…- 18
- 0
-

MOKI-美图推出的AI视频短片创作工具
MOKI是什么? MOKI是由美图在“第三届美图影像节”上公布的AI视频短片创作工具,具备智能剪辑、自动生成分镜图、AI 配乐和音效、自动字幕等功能。它通过 AI 驱动的工作流简化了从创意到成品视频的创作过程,提高视频创作效率。 与常规文生视频产品不同,MOKI 可实现内容和成本的双重可控,目前可以进行多种视频场景的 AI 短片创作。MOKI 可在脚本、视觉风格、角色等前期设定完成后,AI 自动生…- 35
- 0
-

可灵大模型-快手推出的AI视频生成大模型,支持生成2分钟视频
可灵大模型是什么? 可灵大模型是由快手大模型团队自研打造的视频生成大模型,具备3D时空注意力机制,能生成长达2分钟、30fps的1080p高分辨率视频,且支持多种宽高比。它能模拟真实物理世界,转化用户想象为具体画面,并支持多种视频宽高比,适用于多样化的视频制作和内容创作需求。 此外,基于“可灵”大模型,未来还将有更多应用方向即将落地,近期将首发“AI 唱跳”新玩法,可以同时驱动表情和肢体动作,仅需…- 26
- 0
-

StoryDiffusion-字节推出的一致性图像和长视频生成工具
StoryDiffusion是什么? StoryDiffusion是由字节跳动和南开大学合作推出的AI工具,专注于长范围图像和视频生成。它利用一致性自注意力机制来实现图像和视频内容的连续性和一致性。无论是创建漫画、卡通角色,还是生成长视频,StoryDiffusion都能保持图像风格的一致性,为用户提供高质量的视觉内容。通过StoryDiffusion,用户可以轻松地创作出引人入胜的视觉故事和影像…- 19
- 0
-

一帧秒创-专业智能的视频和数字人创作平台
一帧秒创是什么? 一帧秒创是一个以AIGC为基础的效率工具,为图文创作者和营销机构提供一键图文转视频(TTV)服务,通过对优质素材、智能AI语音、智能字幕、BGM、LOGO等匹配设置,无需剪辑,一键成片,零门槛创作视频。 官网地址:https://aigc.yizhentv.com/ 一帧秒创推出了AI数字人服务,地址是:https://aigc.yizhentv.com/ad/ai-…- 48
- 0
视频生成
云图NFT持续分享全球最新优质Al内容,每天更新,欢迎收藏
标签
视频生成-共 0 个作品
今日上传
0个作品






-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×